AWS - S3 Multi Region Access Point
Amazon S3 Multi-Region Access Points provide a global endpoint that applications can use to fulfill requests from S3 buckets that are located in multiple AWS Regions.
You can use Multi-Region Access Points to build multi-Region applications with the same architecture that's used in a single Region, and then run those applications anywhere in the world.
Let's get started. I am going to create 2 buckets each under a different region.

Next, We need to create a multi-regional access point with the 2 buckets.
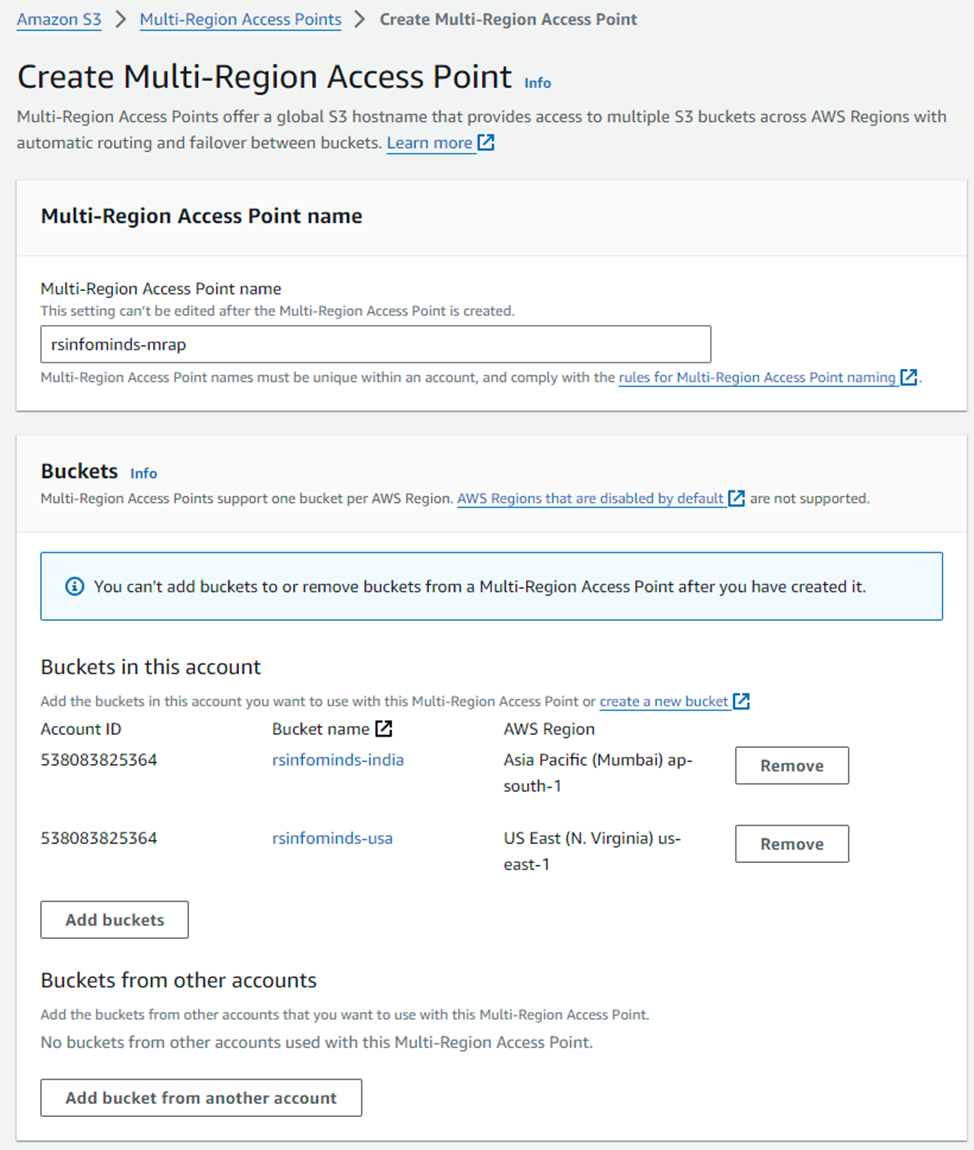
 |


If the buckets are configured using AWS KMS, then the replication has to be configured manually.


Now, We have the replication configured. And we need to setup failover configuration.
There are 2 configurations:
1) ACTIVE-ACTIVE.
2) ACTIVE-PASSIVE.
I am going to set up ACTIVE-PASSIVE.



Next comes the IAM. To access your data in S3 through your Multi-Region Access Point, you need a user with permission to read and write objects to your new S3 buckets, or with permission to assume a role with access.
I am updating the bucket policy to allow access from Multi-Region Access Point ARN.

Next, I update the Multi-Region Access Point policy to allow access for a specific user - Optional.

We are done. Let's test it.

The command is "aws s3 cp file.txt s3://<ARN of MULTI REGION>/file.txt
Verifying the metadata of the object copied.
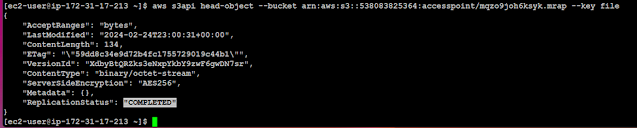
Note: For objects in the scope of a replication rule, the head object will return a value for x-amz-replication-status. Original (source) objects will have a status of PENDING, COMPLETED or FAILED, while replica objects will have the status REPLICA.


Comments
Post a Comment